


How to build a segmentation with k-means clustering and PCA in R
In this tutorial you'll learn how to build a segmentation in R using the k-means algorithm and use principal component analysis (PCA) to perform dimensionality reduction and help visualise our data. At the end we'll combine the results with a decision tree to convert the clusters into simple rule-based segments.

Contents
-
Finding the best value of k for our k-means clustering: elbow method and silhouette score
-
Creating clusters using the principal components instead of the original data
-
Using a decision tree to convert our k-means clusters into simple rule-based clusters
Unsupervised machine learning
In this tutorial we’re going to see how we can build a simple segmentation using the Instacart data from Kaggle. We’ll use k-means to build our clusters and principal component analysis (PCA) to perform dimensionality reduction and help visualise our data. Both k-means and PCA are types of unsupervised machine learning so it’s worth going into a bit of detail of what is meant by this.
'Unsupervised machine learning' means that the algorithm doesn’t have or use any pre-labelled data to work with. There’s no target column we're trying to predict like there would be in supervised machine learning. Unsupervised machine learning algorithms instead analyse our data to find interesting patterns. For example, k-means looks for collections of data points that sit closely together in the data space. PCA transforms our data to a new coordinate system and in doing so creates uncorrelated principal components where the first few principal components capture most of the variance in our data.

The data on the left is an example of unlabelled that we might pass to our k-means algorithm or perform PCA on. Although all the data points looks the same i.e. all 'blue circles', we can see that some points sit together whilst others are further apart. We can also see that there appears to be a weak, positive correlation in our data. Contrast this to the data on the right where we have labelled examples that shows our data splits into two classes i.e. 'blue circles' and 'red squares'. We could then train a model like a random forest or a logistic regression to take in these labelled data points and learn the differences between them.
One important distinction to note between unsupervised and supervised machine learning is that the lack of labelled data makes it much harder to measure how well our model is performing. As we don't have any labels for our data, we can't simply compute how many times we wrongly classified red squares as blue circles or vice versa. We'll look at a few different ways of measuring the performance of our clusters later on but often it comes down to what solution is the most useful or practical rather than having a specific accuracy metric that we're looking to optimise.
The k-means algorithm
To build our clusters we’ll be using k-means but there’s a whole heap of clustering algorithms and the sklearn website has a nice visual summary of the main methods and how they work on different data types. If you’re interested in seeing some of the different algorithms in practice, the Yule’s Q tutorial makes use of hierarchical clustering to represent the associations between products in a category and the spotting credit card fraud tutorial makes use of the density-based algorithm DBSCAN. The k-means algorithm is a great general-purpose clustering algorithm. It’s got some potential pitfalls to be aware of but in general it’s quick and easy to work with which is why it remains so popular.
The ‘k’ in k-means represents the number of clusters we want it to find, which is a parameter we choose in advance and pass to the algorithm. It then works by taking our data and creating k-points at random and then working out for all the points in our data which are closest to each of the random k-points. It does this by measuring the distance in the data space between the random k-points and each data point. By default it uses Euclidean distance i.e. straight-line distance.
Once every data point has been assigned its nearest k-point they’re classified as belonging to that cluster. The original, randomly chosen k-points are then updated and moved so they sit in the centre of their newly created clusters. Each cluster centre is referred to as a ‘centroid’ and is calculated from the average values of all the data points that sit in the cluster. This is where the ‘mean’ bit in k-means. We also record how far the new centre is from our previous one.
As we now have new k-cluster centres, we repeat the first step of finding all of the nearest points and assigning them to their nearest cluster centroid. Since we’ve moved the centre from our random initialisation this means some points will be closer to a different cluster centre now and these points will switch to their new, closest cluster centre. Once all the nearest points have been assigned we re-calculate our new cluster centres and record how far they’ve moved. This repeats iteratively until either we hit a set number of iterations (that we can specify in advance) or the results converge on a stable solution.
Below is an animation of the process from Wikipedia. Notice how at the start the points are mostly red or yellow but then the purple circles cluster grows quickly before the rate of change slows down in the last few iterations as the process arrives at a stable 3 cluster solution:
A 'stable solution' is identified by when we come to update our points at the end of an iteration, we see either no or very little movement i.e. each point is assigned to its closest centre and updating the centre no longer causes any points to move. There’s another great visualisation here that lets you walk-through each iteration in the clustering solution stabilises.
The main advantages of k-means working in this way are:
-
It’s relatively speedy even with big data (not to be underestimated)
-
Relatively simple to implement.
-
You will always get clusters at the end and they will always cover 100% of the data (although this can be a bad thing too!)
The main disadvantages tend to be:
-
We need to specify the number of clusters (k) to use rather than have it find the optimal number for us.
-
By using distance from a central point, k-means always tries to find spherical clusters. It responds poorly to elongated clusters, or manifolds with irregular shapes.
-
As it uses the average distance among cluster member to calculate the centroid, this makes it sensitive to outliers/large values.
-
The random start points can have a large influence on the final solution and means the result can change every time we run it.
-
Given enough time, k-means will always converge/find clusters i.e. it’ll always run rather than flag that the output is no good or the data as unsuitable.
The list of downsides might look quite long but there are some steps we can take to mitigate some of the issues. As it’s relatively quick to run, we can try a range of different k values to see which leads to a better solution. We can also try running the whole process multiple times with different random start points and then just pick the best outcome. We can also attempt to remove or deal with outliers before running the clustering. The main disadvantage is that if our data has an unusual shape (try running it on the 'smiley face') it might just not be appropriate for k-means. This also ties into the last point in the disadvantages list that we’ll always get clusters but we can’t take it for granted that they’ll be any good!
In terms of measuring whether our clustering solution is any good there are a couple of methods we’ll look at. Essentially, they try to measure how compact/close together the observations in our clusters are or how well separated they are from other clusters around them. In reality though the ultimate test for any clustering or segmentation should be: is it useful? Often, you’ll have practical constraints such as not having too many clusters that people have trouble remembering them or avoiding having very small clusters that aren’t useful for further actions.
Defining the business case for our segmentation
As mentioned we're going to be using Instacart data to build our segmentation. Instacart allows users to order their grocery shopping from participating retailers and either pick it up or have it delivered. Let's pretend we've been approached by them to build a segmentation to help them classify customers based on how they shop and use the platform.
For example, whilst some customers buy a bit of everything, some customers only shop certain sections of the store which means they must be going elsewhere for these purchases. Instacart are keen that customers do their whole grocery shop on the platform and as such want a way of identifying 1) customers who are missing out sections of the store and 2) which sections they're missing out. They can then carry out research into why these users are not shopping the full range and potentially send them some offers to get them to cross-shop between categories a bit more.
Having a clear use case is important when doing unsupervised machine learning. Although there are some statistical measures and rules of thumb we can use when assessing our final clusters, what makes a “good” set of clusters will vary depending on the problem we’re trying to solve. Ultimately what should be guiding our analysis at all times is the question “is this useful?” This becomes a lot harder to do if we don’t know what the final clusters will be used for. With that in mind, let's go ahead and load the data and have a look at what categories we've got to work with:
We can see that we've got 21 categories in total with the most popular being 'produce' and 'dairy eggs' with over 190k users shopping them. The least popular category with ~12k users is 'bulk'. We've also got a couple of more obscure category names such as 'missing' and 'other'. One challenge with identifying customers who don't shop the full range is we wouldn't normally expect every customer to shop all 21 categories e.g. we wouldn't expect someone to shop 'pets' unless they had a pet or we wouldn't want to say a vegetarian should be shopping 'meat seafood'. One way to approach this could be to group categories together into more broader categories that between them cover off the different shopping needs we'd expect nearly all customers to have when buying their groceries.
For example, if we think about where we keep groceries in the kitchen we've got fresh produce or things with short use by dates that we might keep in the fridge e.g. dairy, meat, vegetables, etc. We've then also got ambient or longer lasting products that go into cupboards e.g. canned goods, soft drinks, alcohol, etc. We've also got the freezer compartment and then we've got all the non-food items we might buy like laundry detergent, household cleaning products, etc. These categories are probably broad enough that if someone wasn't shopping them or wasn't shopping them much, we'd assume they must be buying those items elsewhere.
The next challenge is to work out what share of someone's orders should go to each category type. How do we define is someone is buying too much fresh products and not enough ambient? We could come up with some business rules using a mix of subject matter expertise and quartiles or averages to define some business rules and then tweak them iteratively until we're happy with the groups. There's nothing wrong with this approach but it can potentially introduce a bit of bias from the analyst e.g. my threshold for classifying someone as not buying many frozen products might be different to yours. The advantage of using k-means is that we can let it identify the clusters and thresholds for us. We'll even see at the end how we can use the clusters created by k-means to convert them back into these business rule type definitions.
Let's have a quick look at the 'other' and 'missing' categories as these don't easily fit into our new categories as outlined above:
They look like a bit of a random assortment of different products. Maybe they're newly launched and so not been tagged with a proper category yet? Working on the basis that going back with the insight that "this customer segment is missing items from the 'missing' or 'other' category" isn't especially helpful we can remove these items from our data set:
Now we've removed the uninformative categories from our data, we can go ahead and create our new more general categories. I've grouped the products into ambient, fresh, frozen and non-food based on looking at the sorts of products that are in each department and also on the Instacart website. There's maybe an argument to be made for having the 'babies' department in ambient as there's a lot of jars of baby food but equally there's lots of products such diapers.
At the moment our data is still at a 'user - order - product' level whereas we're more interested in general categorisation of users based on all of their purchases across all of their orders. We can aggregate the data up to a user level rather than an order level as although we might not expect a user to order non-food products every time they shop e.g. rarely do you need to buy laundry detergent every week, over the course of all their orders we'd at least expect to buy it some of the time. Let's aggregate the data up to user level and create some metrics we think will be useful for our clustering.
Since we're investigating whether or not users shop a wide range of products I'll count the unique number of products, aisles and departments a user has shopped as well as the number of orders they've placed and the average number of products they tend to purchase in an order. These will capture how often a customer shops and how broad an assortment they shop. Next I calculate what percentage each of the total items someone buys come from each of the main categories we created earlier.
I could have instead counted the number of products someone buys from each category but to an extent that's already captured by the total number of items a user buys. For example, if someone buys a lot of products in general they're probably likely to also buy lots of products from each category. What we're interested in though is do customers buy a mix of products from each category i.e. a balanced split of products across the categories rather than just do they buy a lot from each category.
We can see from the print out above for example how user 1 didn't buy any frozen products despite placing 10 orders. Now we've got our data aggregated we can call a quick summary() on it to see how the different distributions within the data:
We can see that the fewest orders a customer has is 3 and the maximum is 99. Likewise some customers have only ever shopped one aisle whereas others have managed to shop over 100! We can see as well the average percentage of items bought from 'fresh' is over 50% suggesting that it's a popular or large areas of the store. By comparison 'nonfood' and 'frozen' are pretty small categories and yet there are still customers who managed to order 100% frozen items. We'll look at how we can deal with these extreme examples in the next section.
Data prep: missing values, correlations, outlier removal and scaling
Missing data
Now we've aggregated our data let's have a quick check for any missing values. Like a lot of machine learning algorithms, k-means will error if it encounters missing data. Let's confirm we've not got any missing data in our example:
Nice! If we did have some missing data, a simple option is to replace any missing values with the average value of the column. We can do this with the recipes package from the tidymodels collection of package from RStudio. If you'd like to learn more about tidymodels there's a separate tutorial on it here. For our purposes we simply define a 'recipe' that tells tidymodels to replace all the missing values with the average from the column.
First we call recipe() and provide a formula to help tidymodels identify which columns we want to have any missing data replaced in. The 'formula = user_id' tells tidymodels to ignore the user_id column whereas the ' ~ .' tells tidymodels to treat all other columns as candidates for imputation. We also tell tidymodels what data set to use with 'data = category_data'.
Next up we specify how we want the imputation to happen 'step_impute_mean()' as the name suggests uses the mean of the column. The 'all_predictors()' is just a quick way of telling tidymodels to do it for all columns other than 'user_id'. The prep() and bake() steps then calculating the mean values (in prep) and then apply them to our data (bake). I'm not saving the output or assigning it to an object simply because we don't need to as we didn't have any missing data.
If using the average of the column seems a bit simplistic we can make use of the more advanced imputation methods available in tidymodels too. Instead of the mean, we can tell tidymodels to run a bagged tree model to predict any missing values. This approach takes a lot longer so rather than run it for all columns by default, let's pretend we've only got missing values in 'num_order' and 'products_per_basket'. The code is largely the same except we change the impute step and pass a vector of column names this time:
Correlated variables
Now we've removed any missing data it's a good idea to have a look at the correlations between our inputs. If we’ve got any highly correlated features we might consider removing some of them. This is because they’re essentially doing a similar job in terms of what they’re measuring and can potentially overweight that factor when k-means comes to calculate distances. It’s not a definitive requirement and we can always experiment with running the clustering with any highly correlated features included and removed.
The highest correlation we have is between ‘number of aisles’ and ‘number of departments’ at 0.89. Since aisles ladder up into departments it maybe makes sense to remove one of them. Since we’re trying to capture how much of the assortment people are shopping with these two features let’s keep number of aisles as it has a higher ceiling in terms of how many people can shop.
Outliers
Next up we can deal with any outliers in our data. In the tidymodels and caret tutorials I cautioned against blindly removing outliers to try and boost a model score but for clustering I take a more laid-back approach. This again comes down to what do we want to use our clusters for eventually. Since we’re trying to find people who don’t shop the full assortment I’m less worried if we have some extreme users who buy nothing but cat food vs users who buy every product in the shop.
The treatment/decision we’d apply to those users will be exactly the same as someone with more moderate behaviour i.e. they’d both sit in a “doesn’t buy much” or “buys loads” cluster even if their own behaviour is extreme within the cluster. As their extreme behaviour doesn’t change how I’d want to classify them but can potentially interfere with where the cluster centroids end up, I’m happy capping/removing any extremes in the distribution to help k-means create sensible clusters. For this tutorial I’m simply going to cap any values at the 1st and 99th percentile for each input.
We can see how the min/max values for a lot of the columns change with the removal of the outliers but in general the mean values show little change.
Scaling/standardising and transforming
Another important step in clustering is to standardise the features so that they’re all on the same scale. As clustering uses a notion of ‘distance’ to work out what observations are close to others it makes sense that each feature it uses to calculate this distance needs to be comparable. For example, say we have a percentage value that ranges from 0 to 1 but also a spend value that ranges from £100 to £10,000. If left in their raw form the algorithm would potentially see the highest spend value as being 10,000 further away than someone with the maximum percent value.
If we create boxplots of each of our features as they currently are we can see how the ‘num_aisles’, ‘num_order’ and ‘products_per_basket’ dominate the distribution as these are integer values compared to all our category data which can only be between 0 and 1:

A common way to rescale our data so they all contribute equally is to standardise each of the inputs with a z-transformation (subtract the mean and divide by the standard deviation) so that all the input variables have a mean of 0 and a standard deviation of 1. This way all the features contribute in an equally weighted manner when k-means tries to work out the distances between observations.
Another option is combine the normalisation with a transformation of the data to try and give it a more ‘normal’ shape. For example, we could use a power transformation like Box-Cox or Yeo-Johnson to try and give our data a bit more of a normal shape before scaling. Whether we decide to transform or just normalise our data, we can use the tidymodels package to do our data prep for us just like when we did our imputations:

Reduce dimensions with Principal Component Analysis
Principal component analysis is a useful tool for reducing down the number of dimensions in our data whilst preserving as much information as possible. A handy benefit is that the principal components we create are also uncorrelated with each other. We’ll first see how PCA works and then how we can use it on our data.
There’s a great StatQuest here that will do a better job than me explaining the technical side of how PCA works and there’s a great 3Blue1Brown video on the linear algebra behind it here. There's also this site which has an interactive visualisation of how PCA works and let’s you play around with the data points and see how it changes the principal components.
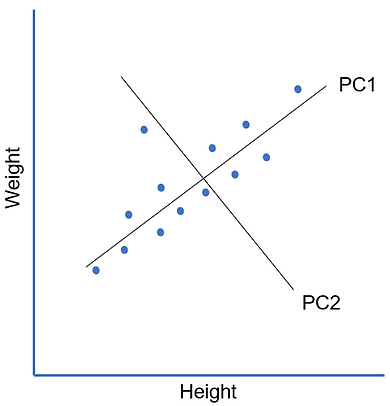
Essentially what we’re doing with PCA is replacing our original features with new principal components that are linear combinations of the original features. That phrase ‘linear combination of features’ might sound familiar if you’ve done linear regression before but whereas linear regression is a supervised machine learning technique, PCA is unsupervised. Instead of trying to predict a target ‘y’ instead what we’re trying to do is explain the variance that we see in our data. We can get an idea of how it does this from the chart below. To keep things simple I’ll just use some made up data with 2 dimensions - height and weight:

We can see from our chart that there’s a strong linear relationship between the two dimensions. We can also see that the data is more spread out along the ‘height’ dimension than it is the ‘weight’ dimension. We have some data points that are relatively short in height and some that are a lot taller. For weight there’s a bit of a spread but not too much. So how could we go about summarising the information contained in our data set?
Well, we could draw a line that captures the relationship we are seeing of the positive linear trend between height and weight and the fact that most of the spread in the data is occurring on the height axis. We fit it so that the orthogonal distance (distance measured at a right angle or 90 degrees from our line) between our data points and our line is minimised. Remember in PCA, we have no target we're trying to predict, rather we're trying to find lines that capture the information in our data.

This first line captures a lot of the information contained in our data. Our line can be expressed as a linear combination (just a weighted sum) of our height and weight dimensions. For example the line is a bit flatter so it might be something like 'PC1 = 0.9*Weight + 1.1*Height' and we see that it is a good approximation of our data i.e. it explains a lot of what is going on in our data. This line is our first principal component (PC1).
However we also see that some points sit above the line and some sit below. To capture this extra bit of information we can add a second principal component that captures the “above or below” aspect in our data. Looking at the spread when computing principal components is the reason why we need to standardise/scale our data before applying PCA to it. If we had dimensions with different scales then the dimension with the larger scale would automatically account for more of the spread in our data and so always become PC1.
To construct our second principal component we draw another line orthogonally (at 90 degrees) from our original line. This is what makes our principal components be uncorrelated with each other. This second principal component allows us to capture the information missed out by the first one but overall captures a much smaller proportion of the variance (because there isn't as much variation in this second dimension). As part of finding the principal components, the PCA process rotates our data so that the component that explains the largest variance in our data is on the horizontal axis and the second PC is on the vertical. It also centres the data so the mean is 0 so technically our data with the two principal components looks like the plot on the right:
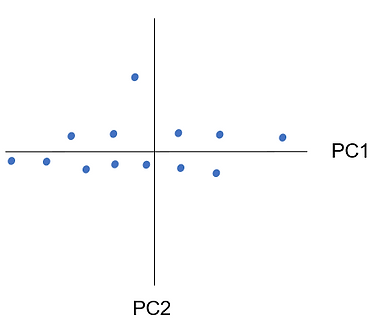
As PC1 gives us a good approximation of our data we might choose to not bother with PC2. This is how the dimensionality reduction aspect of PCA works. We only need to pick as many PCs that capture a ‘good enough’ view of our data. For example, if we chose to represent our data just with PC1 and essentially discard the PC2 component this is how it would look:

We can see that although we do lose some information about how our data is distributed we can still capture a lot of the information about which points are far away from each other and the general spread of our data. Sometimes our data will mean we need more principal components to explain all the variation in our data. For example, compare the plots below:


We can see on the first plot, PC1 captures most of the information i.e. it varies a lot on one dimension but only a little bit on the second dimension. The plot on the right however has a lot more variability on the second dimension so our first principal component, although still explaining the most, gives us a lot less. In the second example we might decide we want to keep the second PC and so we’ve not actually been able to reduce any dimensions.
Notice as well that what we’re capturing with our principal components is linear relationships in our data. If we had non-linear relations e.g. if our data made a circle on our scatter plot or was very wiggly our principal components would struggle a lot more to explain what was happening in the data.
At the moment we've been working with 2D data but the approach is exactly the same for however many dimensions we have. If we had more dimensions in our data we'd simply add more principal components to capture the variation seen in those new dimensions. Now, let's have a go at applying PCA to our data.
Since we’ve already standardised our data ready for clustering, we can go ahead and run PCA on it using the prcomp() function from base R. We’ll set ‘center=F’ and ‘scale=F’ as we’ve already taken care of this with our pre-processing recipe. We can also call the summary() function on our newly created object to understand the amount of variation that’s explained by each principal component:
We can see that the first two principal components between them explain 55.7% of the variance in our data which is pretty good. By having just 3 principal components we can explain 71.6%! We can also see the ‘loadings’ of the variables on each of the principal components. This shows us the linear combination of features for each principal component i.e. how each feature in our data contributes to each principal component. We can plot PC1-3 to see which features contribute most heavily to each principal component to try and get an idea of what each one is representing from our data:

We can see that PC1 has a strong positive loading for 'ambient' as well as negative loadings for 'fresh' and the features representing how often and how broad users are shopping e.g. 'num_aisles', 'num_orders' and 'products_per_basket'. It might be capturing customers who don't shop a wide range of products and tend to buy a higher percentage of ambient goods. PC2 has a strong loading for 'fresh' and PC3 a strong negative loading for 'frozen'. We can start to see how different behaviours e.g. primarily fresh/ambient/frozen shopping user behaviour can be represented by just the 3 principal components.
Another neat application of PCA is to use it to visualise our data. We can apply PCA to our data with a recipe in tidymodels and then visualise it using the first two principal components:

We can see that our data looks pretty blob like! This can be the challenge when working with real life data that a lot of the time, although we know there are different behaviours going on in our data, they’re not nicely separated into distinct groups. However, it’s our job to work with the messy data to determine sensible groups for the business to use.
Creating clusters with k-means
Let's have a go at creating our first group of clusters. To do this we'll use the kmeans() function from base R. I'm going to try a 5 cluster solution to start with. Generally you'll want to try a few different values of k and we'll see later how we can use some of the handy inbuilt measures of fit to determine the optimal value. There are quite a few options that we specify in the function too so we can go through each of those in turn.
First we pass the data set we want to build our clusters on. We're using the transformed and scaled version of our data and I drop the 'user_id' column. Next up we have 'centers' which is the number of clusters we want. The 'nstart' option specifies how many different random start point configurations we want to try for our clusters. Remember that k-means picks randomly generated centroids at the start and then assigns the points and updates the centres iteratively. Depending on where the initial random centroids are generated, we could end up with different cluster solutions between runs. One way round this is to run the process multiple times, we different random start points and then pick the solution that gives the best clusters.
The 'iter.max' option sets a ceiling on how many times we want the iterative process of assigning points and recalculating the centroids to run for. Hopefully our solution will converge on a stable solution before the 200th iteration but kmeans() has a default of 10 which can sometimes not be enough iterations for a stable solution to be found. Finally we pick the algorithm which is the version of the k-means algorithm we want to use. Usually I'd just leave this one as the default but when trying it out on the data, due to the volume and how close a lot of the points are it was giving warnings so I've set it to "MacQueen" instead. Now let's go ahead and create our clusters:
We get quite a lot of information in the print out as well as a note about some extra "Available components" which we'll make use of in the next section. At the top we can see the size of each cluster. It looks like we've got three smallish clusters ranging from ~12k to 37k users each, a medium cluster with just under 54k users and one big one with 78k users. Depending on your data and what you're trying to achieve, very small clusters can sometimes be a sign that we've picked too large a value of k.
We can also see the cluster centroid values i.e. the mean value of each input for each cluster. This is slightly hard to interpret as it's on our scaled data but we can see for instance that cluster 1 and 2 score very strongly on 'nonfood' and 'frozen' respectively which may in part explain why they're so small. Cluster 5 has the highest average value for 'num_order', 'products_per_basket' and 'num_aisles' so might be representing frequent customers who shop a lot of categories. Cluster 4 seems to more be about customers with a higher percentage of ambient products. We also get a long print out which shows the cluster for each user in the order they occurred in the data which we'll use shortly.
After that we see a 'Within cluster sum of squares by cluster' (WSS) which measure how closely the observations in each cluster sit towards the cluster centroid i.e. how compact each cluster is. Essentially for each point you work out the straight line distance between it and its cluster centre and square it and then sum this for all observations in the cluster. The idea behind clustering is to group similar data points together so we'd hope that each point in the cluster is similar to all the others and so similar to the average for the cluster i.e. the distance between each point and the cluster centre should be low. Interpreting the WSS in isolation though can be tricky as a lot of the within cluster sum of squares size depends on how spread out our data is in general and also on its scale. One way to measure it is to compare the WSS between different cluster solutions which we'll see next.
The (between_SS / total_SS = 33.7 %) shows what proportion of the total variance in our data is captured by the variance between clusters. In our case it's 33.7% and ideally we'd like this percentage to be as high as possible as it means we have well separated clusters i.e. large gaps between them. As ours is on the lower end it might mean that either our clusters are quite close together which is likely the case given how blob-like our data was in the PCA plot. Let's merge on our clusters to our original, unscaled data to better visualise the differences between the clusters:

Similar to our interpretation of the cluster averages on the scaled data, we can see that cluster 1 is the 'nonfood cluster' and cluster 2 the 'frozen cluster'. In fact it looks like each cluster has pulled out a specific category as its niche e.g. 'fresh' cluster 3 and 'ambient' for cluster 4 with cluster 5 capturing the 'shops a lot' behaviours. This could potentially be helpful for our business case of identifying users that aren't shopping as much in each category. On the other hand we saw we had some quite small clusters which might add unnecessary complexity to the solution i.e. more groups to survey, more segments to remember and maintain, etc.
Finding the best value of k for our k-means clustering
So far we've had a look at the 5 cluster solution which looked like it was doing a pretty good job of finding different user groups. Let's now try a few different values of k to see if we can find an even better solution. There are a couple of statistical methods to identify good clustering solutions which we'll run through now but the ultimate test should be whether or not the final solution will be useful and help us solve our business case.
The first method we'll look at uses the within-cluster sum of square (WSS) measure that we saw earlier. We can sum up each of the within-cluster sum of squares to get a total WSS for our solution. The kmeans() function actually does this for us and you can see it listed as one of the available components in our original output: 'tot.withinss'. What we can do then is run different clustering solutions with different values of k and record the total WSS value each time.
One thing to be aware of is that the total WSS value should decrease every time we add more clusters by virtue of the fact that having more, smaller clusters will make them more dense. This means it's not just a case of picking the solution with the lowest total WSS. Typically how we use the measure is to plot the total WSS for each cluster solution so we can track the decrease for each extra cluster. As a rule of thumb we can then pick the solution at the 'elbow' of the plot i.e. the last value of k before we see the decrease in total WSS start to tail off. Let's see how we can easily do this
We can see that for each extra cluster we add to the solution the total WSS decrease. We can also see from about 7 clusters onwards the drop isn't that much compared to earlier solutions. Let's plot the results to make it more obvious where the results start to tail off:

The plot is referred to as an 'elbow plot' as we're looking for the point where the increase in complexity of adding an extra cluster doesn't result in as much of a drop in total WSS as previous values of k although for our plot it's not super clear where the elbow point is! This can be one of the challenges when trying to cluster real world data. It looks like we might even have two possible elbows at 3 and 5 clusters. We can see that the total WSS drops quite quickly up to 3 clusters and then tails off a little bit between 3-5 clusters and then becomes very shallow after 5 clusters. This might suggest exploring 3 clusters as another possible solution.
Another method for finding the best value of k is called the 'silhouette score'. The silhouette score compares how similar each data point is with all the other data points in its own cluster (mean intra-cluster distance) vs how similar the point is compared to all the data points in the next nearest other cluster (mean nearest-cluster distance). We can then take an average of all these scores to get an overall value for the clustering solution.
The average silhouette score can range from -1 to 1 and a higher value is better. The sklearn documentation has a good description of the exact calculation. If the clustering solution is good what we’d hope is that each point sits closely to other points in its cluster (good compactness) but also be far away from points in other clusters (good separation).
The downside with this approach is because we need to calculate the distance for every data point against a lot of other data points (all points within the cluster and all points in the next nearest cluster) it can use a lot of memory. The silhouette() function in R can often run out of memory on large data sets so we'll run it on a 10% sample.
What we get is a print out for every row in our data set that shows the current cluster for the observation, the 'neighbor' or nearest other cluster and finally the silhouette calculation for the point. We can see that a lot of our scores are fairly low which means although our points are closer to their own cluster members which is what we want, they're also quite close to points in other clusters too. This is one of the challenges with working with behavioural data like we are in that there's probably fairly limited way in terms of how users can shop the site so all behaviours sit quite closely together.
We can plot the results for our 5 cluster solution to see the silhouette score for each observation in each cluster. This can be useful as we'd hope that most of the points score highly and also the scores are fairly consistent within the clusters. If we have some points with low scores this suggests we've got close or overlapping clusters and a score<0 is a sign that the point might even be in the wrong cluster.

We can see that the average silhouette score for the 5 cluster solution is 0.234 with most clusters apart from cluster 5 being around that too. Clusters 2 and 5 have the highest number of users with a score <0 meaning that potentially these users would be better off in a different cluster. Let's try running our silhouette score calculation for some different values of k and we'll record the average score and plot the results. Remember that a higher value is better for the silhouette score:

Picking a final value of k
From the final silhouette plot we can see that our original 5 cluster solution has the highest average score. A 5 cluster solution also looked like a good choice from the elbow plot. So does this mean we should pick 5 clusters and call it a day? Although the elbow plot and silhouette score are handy guides as to how dense or well separated our clusters are, ultimately we want to create something that adds value to the business.
Suppose after speaking with our stakeholders, 5 clusters is more than they were expecting and maybe they have a requirement that each clusters needs to be of a minimum size to be useful. For example, unless the customers buying lots of frozen products are particularly important or valuable that cluster might be too small to be of any help with the business case. Let's try going with 3 clusters in the hope that they're all of a good size and they it seemed to give us a bit of an elbow in our first plot.

We can see from the output that cluster 1 buys a high proportion of fresh items but not much ambient. Cluster 2 buys a more even split of fresh and ambient and also shops a larger number of aisles and tend to buy more products per order too. Cluster 3 buys more ambient and the smallest proportion of fresh. The smaller categories like frozen and non-food are pretty evenly distributed across the clusters with cluster 3 maybe buying a big more non-food on average. We can repeat the plots but this time use the scaled data that went into the clusters to see how the different features vary within their own clusters:

Remember that we scaled the data to have a mean of 0? Well we can see that for cluster 1 the fresh category is in general much higher whereas for cluster 2 the category splits all centre around 0 suggesting they shop an average amount in each category but it's their number of orders and products per basket that are a lot higher. Finally cluster 3 is very strong on ambient and much less on fresh and things like number of orders.
Looking at the plots it looks like we can get a pretty good idea of the different behaviours that are driving the clusters. Cluster 1 are potentially buying their ambient, frozen and non-food goods elsewhere. These categories can sometimes be a bit more functional and easier to shop around for e.g. it's much easier to compare the price difference between retailers for the same pack of branded dishwasher tablets than it is say the freshness or quality of a steak.
Cluster 2 buy a bit of everything and shop often so they'd be our ideal users from a 'shop the whole assortment' point of view. Finally cluster 3 are almost the opposite of cluster 1 and don't buy much fresh produce but do buy more ambient and even a bit more non-food. Potentially these could be customers using Instacart to buy bulky or heavy ambient goods as it's convenient but then they tend to buy their fresh produce elsewhere. This could be something we suggest to Instacart to look at in their research.
Let's quickly check the size of each cluster to see if we've hit the brief that we don't have any really tiny segments:
Those look pretty good! The good news for Instacart too is that the bulk of users fall into cluster 2 who buy a bit of everything. Earlier we saw how we could plot our data using the first two principal components. Now we can do the same but this time we can colour the points to match their cluster:

We can see we've succeeded in getting 3 fairly evenly sized clusters that each occupy distinct areas of our plot. We can see that each clusters shares a fairly messy boundary with the others which is probably why our silhouette score was so low. In an ideal world we'd have nice, self contained groups but on the other hand the cluster profiles showed 3 fairly distinct, interpretable and useful patterns of behaviours that met our business case of finding customers who don't shop the full range of products and which types of product they're missing out.
As a business we'll always need ways to categorise customers and treat them differently even if their behaviours aren't as discrete as we'd like. For example, a customer spending £1,000 a year might be classed a VIP customer whereas the one spending £999 wouldn't even though there's only £1 i.e. not much distance in it.
Running k-means after PCA
As well as using PCA to help visualise our clusters we can also use the principal components as inputs into the clustering. This can sometimes be an advantage as we can use fewer features and possibly remove some of the noise from the original data. We saw earlier that we only needed 3 principal components to capture over 70% of the variance in our data so we can try clustering just using those. Let’s reuse our 3 cluster solution code but pass it the PCA data set this time:

The clusters look very similar to our original ones on the raw data which is reassuring! The main difference seems to be the blue is now on the left and the green on the right which will be down to R picking different random starting points as it's working with new data. It looks like they converged into the same groups as on our raw data though. Let's check this to see how well the two different solutions match:
It looks like cluster 2 and cluster 3 have been labelled differently between runs so let's fix that and recompute the cross-tab:
Looks like between 99% of all our observations end up in the same cluster whether we use our original data or just the first three principal components. In this case I’d probably choose to present the non-PCA solution back to the business as it’s a lot easier to answer the question of what went into the clusters if we have the original features.
Convert clusters to business rules using a decision tree
Finally let's try using a decision tree to translate our clusters into an even easier to understand set of business rules. The decision tree will take in our original, untransformed features and try to predict which cluster each user belongs to. We pass the cluster as a factor so rpart knows this is a classification problem. We're essentially using rpart to solve the classification problem 'what cluster is this user in' to derive rules that best map users to their clusters using the original features.
This has the advantage of making our final segments easier to explain to stakeholders and also removes some of the ambiguity from users that sat of the edges of the clusters of which we know there are a few. We can use the rpart package that we loaded at the start to create our decision tree and the rpart.rules() function from the rpart.plot package to easily extract the rule the tree finds:
We can see we get a confusion matrix that shows how well the rules the model found classify our users into their correct segments. For example 92% of users predicted to be in cluster 1 are correctly assigned to their cluster by the following rule: "shops fewer than 28 aisles and buys 54%+ of all their products from the fresh category". We can see our accuracies vary between 88%-92% which is pretty good considering the rules themselves are pretty simple. Let's code up the rules and confirm that we get the same match rate:
It matches! The other advantage of translating the clusters into simple rules like these is we can easily assign any new customers to a segment. We've pretty much come full circle in terms of creating business rules to help identify our different groups. The benefit of doing it this way though is rather than iteratively testing lots of different rules and then applying them to our data, we let k-means find relevant groups in our data from which we derived the rules.
If you'd like to see some other types of clustering in action, this tutorial on Yule's Q uses the same Instacart data to find associations between different products. There's also this tutorial on how to use DBSCAN to spot credit card fraud.